Open Source Repository
https://github.com/RLsys-Foundation/TritonForge
Contributors
Jin Pan, Xiang Long, Chengxing Xie, Kexun Zhang, Haoran Wang, Junrong Lin, Yuzhen Zhou, Jiajun Li, Yang Wang, Xiaodong Yu, Gowtham Ramesh, Yusheng Su, Zicheng Liu, Emad Barsoum
1. TL;DR
TritonForge is a Server-based RL training and evaluation closed-loop system designed for multi-turn Agent tasks, built on the slime (SGLang-native) + Megatron foundation. It focuses on Triton kernel generation with stable and scalable practices across both NVIDIA and AMD ecosystems. The design goal is to transform “the instability of multi-turn RL in real-world environments” into implementable, scalable, and maintainable system capabilities.
Regarding methodology and task design, we draw inspiration from Kevin (multi-turn RL for generating CUDA kernels) and KernelBench (kernel correctness and performance evaluation benchmark) — representing the multi-turn RL training paradigm and engineering evaluation standards, respectively.
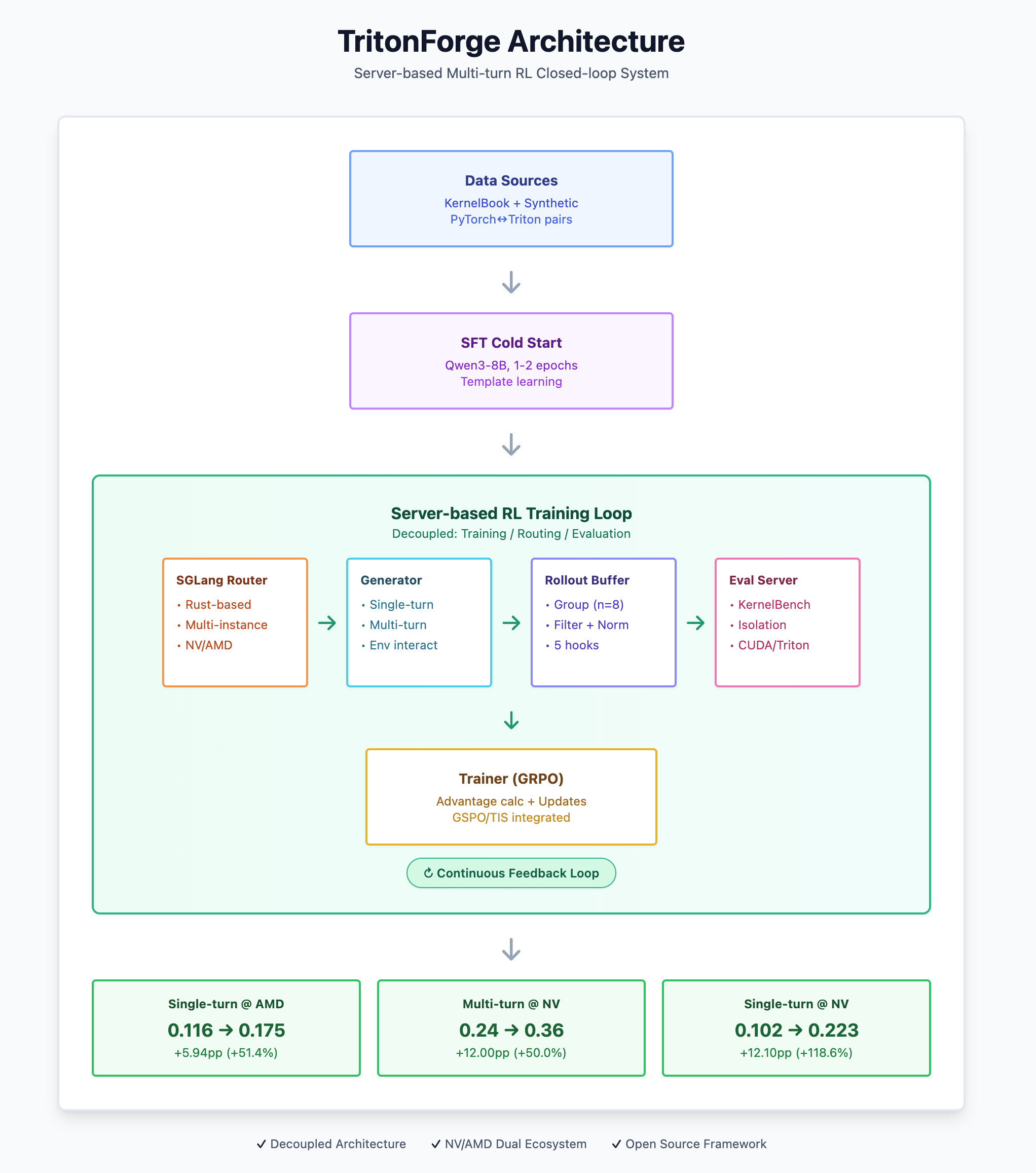
- Architecture Philosophy: The Server-based design decouples training/routing/evaluation; SGLang Router natively supports multiple inference services and high concurrency; Buffer operates in “group” units performing multi-sample sampling (e.g., n=8) -> filtering -> normalization -> padding, unifying the raw_reward standard.
- Methodology Overview:
- SFT cold start (KernelBook-style data; extreme-length sample filtering to avoid OOM);
- RL (primarily GRPO, with GSPO/TIS integrated for future horizontal comparison);
- Eval Server based on KernelBench backend with engineering enhancements (subprocess isolation, timeout/fault classification, CUDA/Triton dual backends).
- Early Results (on Qwen3-8B-fine-tuned):
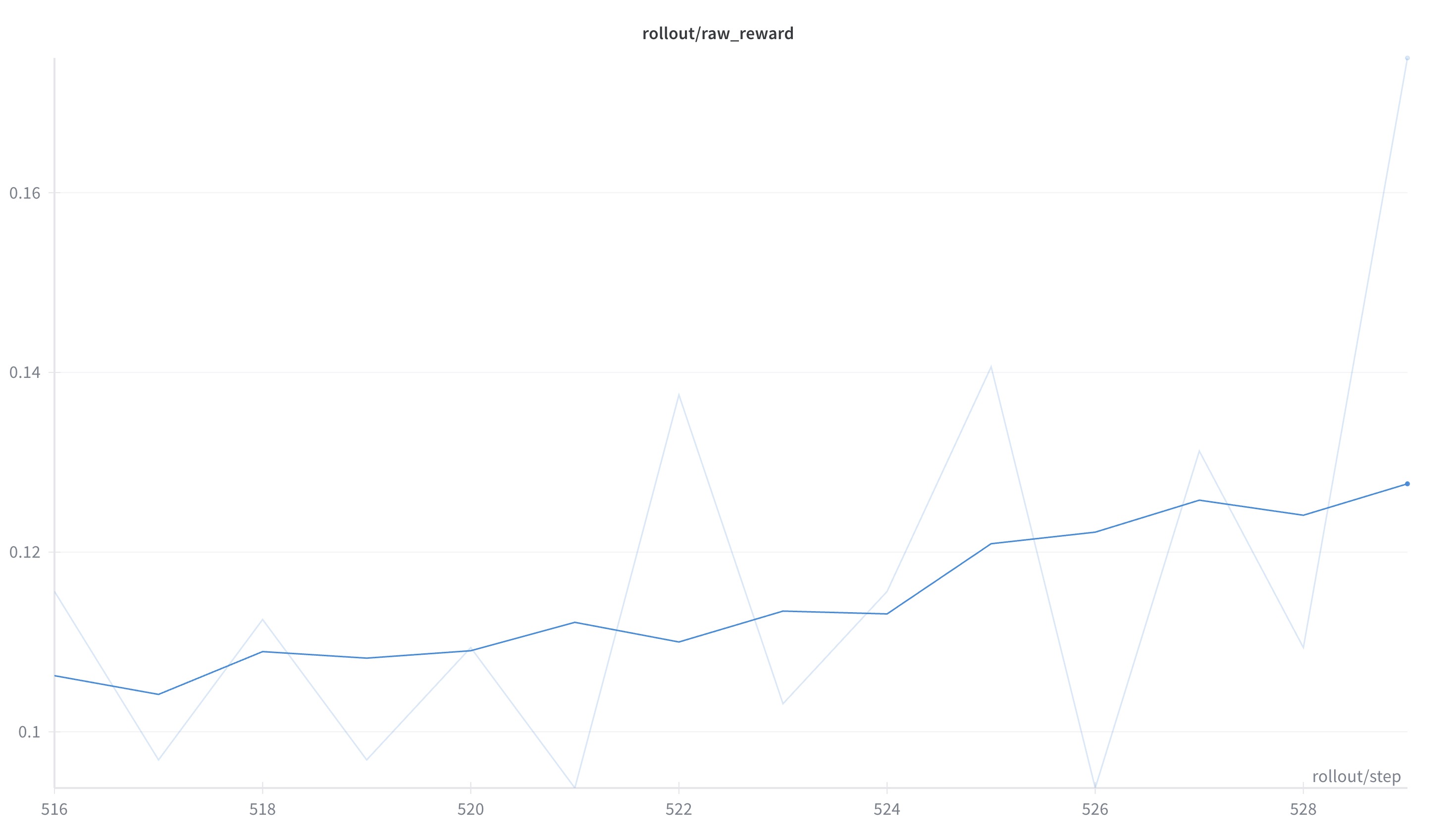
- Single-turn @ AMD: 0.116 -> 0.175, +5.94 percentage points (approx. +51.4%)
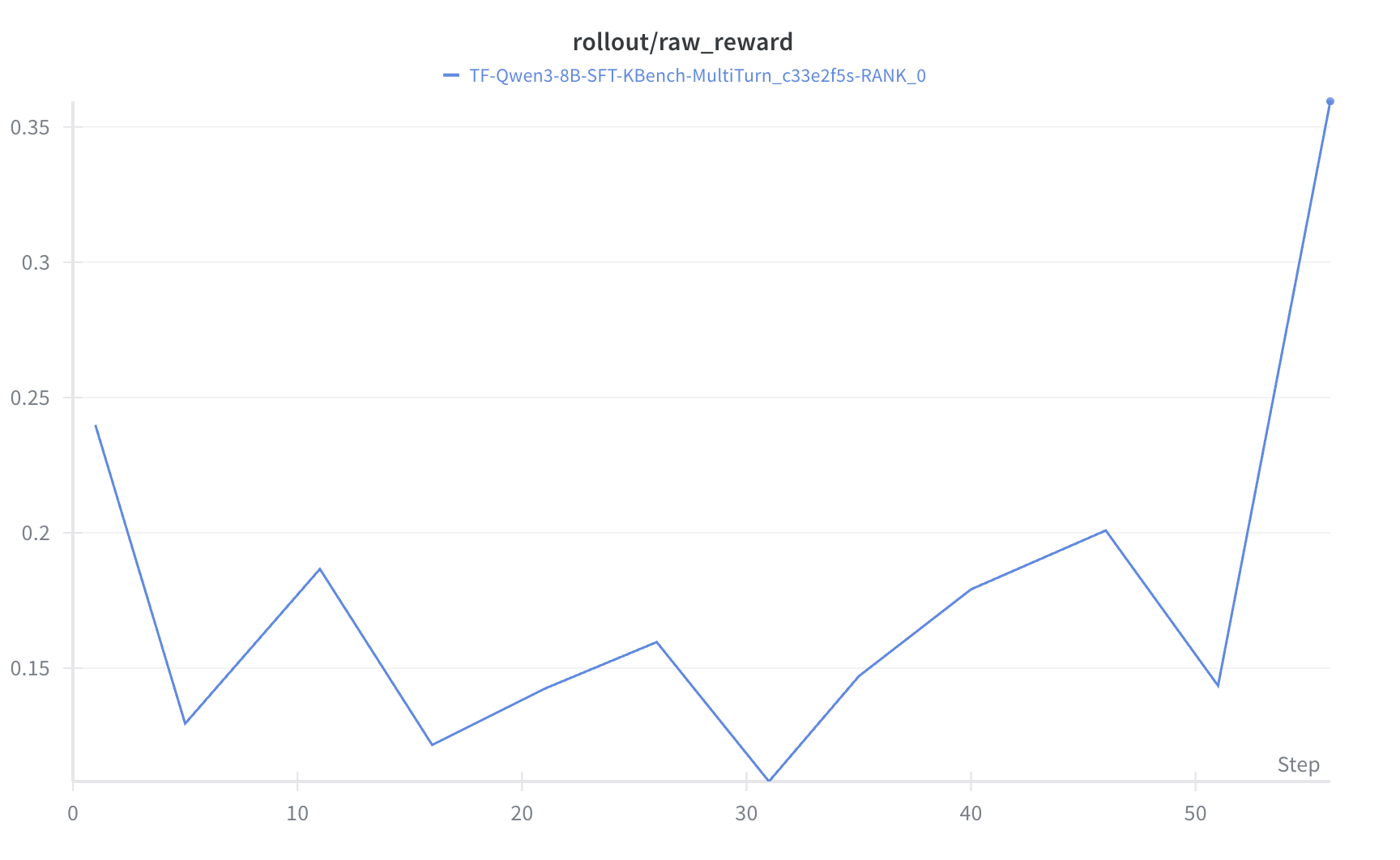
- Multi-turn @ NV: 0.24 -> 0.36, +12.00 percentage points (+50.0%)
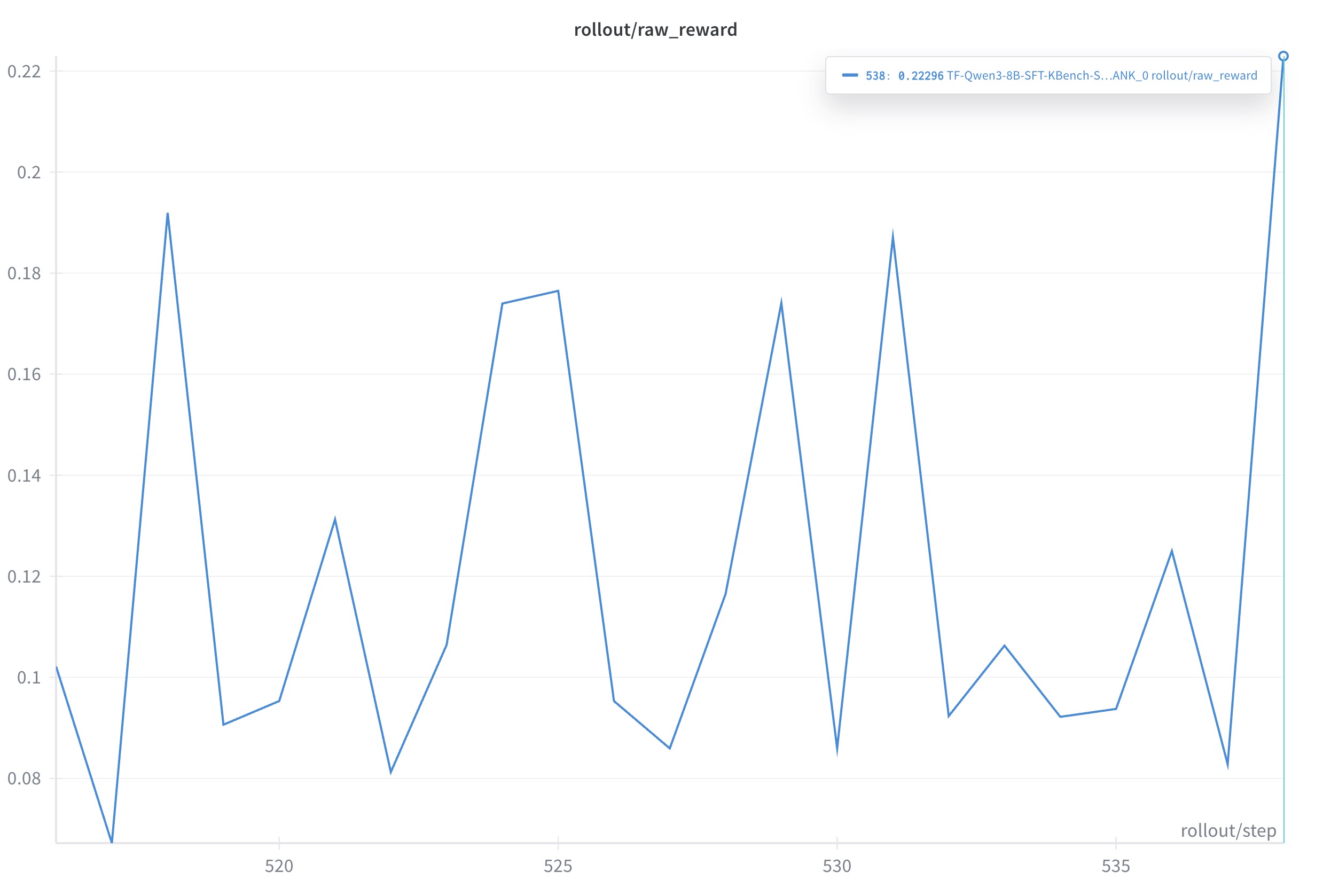
- Single-turn @ NV: 0.102 -> 0.223, +12.10 percentage points (approx. +118.6%)
- Multi-turn @ AMD: Issue identified, currently being fixed
- Open Source and Scalability: We have open-sourced the end-to-end Server-based framework and slime_plugins (single/multi-turn kernel generators, Buffer five-component hooks), using the slime + SGLang paradigm to facilitate future plans for integrating more algorithms (GRPO/GSPO/TIS/…), MoE models, and complete Agentic tool-calling workflows.
- Recommended Reading (Inspiration Sources):
- Kevin: Multi-Turn RL for Generating CUDA Kernels (training framework built on closed-source OpenRLHF + vLLM + DeepSpeed ZeRO-3, adapting multi-turn RL to real environments and long trajectories)
- KernelBench: Can LLMs Write Efficient GPU Kernels? (250 PyTorch-CUDA scenarios, evaluation framework and metrics design balancing correctness and performance)
- KernelBook / KernelLLM: PyTorch <-> Triton paired sample dataset; includes KernelLLM (Llama-3.1-8B-Instruct); inspired us to adopt the SFT cold start -> RL approach — Dataset
2. Technical Choices
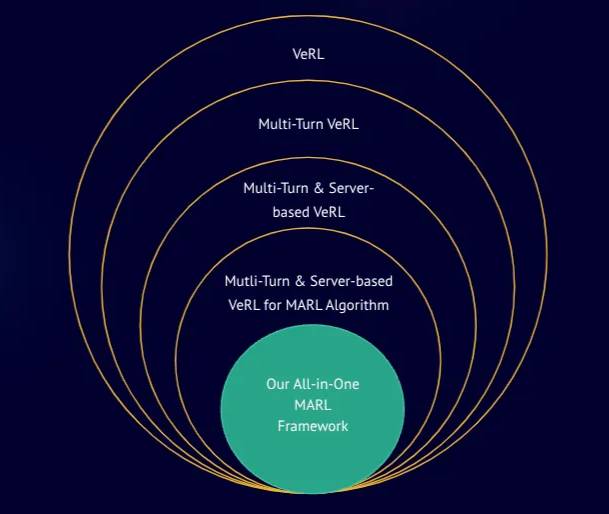
2.1 Why Slime? (From verl to slime)
Where we started
We initially planned to build the full multi-turn RL pipeline on veRL:
- veRL had already merged SGLang asynchronous multi-turn rollout support (PR #1037), which aligns closely with our goal of training multi-turn agents.
- In parallel, we submitted an SGLang PR (#4848) to explore native server-based rollouts within veRL.
- Our early design docs were modeled on a fully server-based framework (IPC, async parallelism, decoupling from the agent environment, etc.). Design Doc
- We also discussed a comprehensive veRL x SGLang roadmap with community collaborators. Discussion
Real-world constraints and engineering trade-offs
- In May, the community released solutions packaged on a fixed veRL version (e.g., SkyRL). These work well in certain environments, but our internal evaluation required additional integrations such as AWS Cloud / OpenHands. The overall go-live threshold was higher, which wasn’t ideal for quickly “wiring end-to-end” a server-based multi-turn training loop in the short term. Code & docs: SkyRL
Why we pivoted to slime:
- SGLang-native, server-based, clean by design: Slime naturally decouples training from inference/routing with a lightweight interface, letting us spin up and orchestrate Rollout Buffer / Eval Server as independent services.
- Execution velocity: Without sacrificing extensibility, Slime let us stand up the closed loop of “multi-turn agent in a real environment -> evaluation -> training” more quickly and open-source it step by step.
- Long-term evolution: Slime’s plugin design (generator + the buffer’s five hook points) meshes well with SGLang Router’s multi-backend routing — fitting our roadmap for MoE, more RL algorithms, and agentic tool-calling.
Summary: This wasn’t “abandon A for B.” To rapidly stand up a maintainable, server-based multi-turn RL loop, we chose the more pragmatic engineering path — slime — while continuing to keep good interfaces and interop with the veRL community.
2.2 Why Server-based
Core need: Multi-turn agent training faces long trajectories, heavy tool dependencies, and real-world uncertainty. A server-based architecture fully decouples model inference/training control from the environment/evaluation, offering the best balance of stability and scalability right now.
- Decoupling & portability: The agent environment can run on another machine / in another language; the model side can upgrade freely (different frameworks, GPUs, parallelism strategies) without affecting environment logic.
- Native async & elasticity: Requests/responses are managed over the network, making concurrency scaling and elastic scheduling straightforward; training bubbles are reduced and GPU utilization improves.
- Routing & governance: SGLang Router (Rust) manages many high-concurrency inference services and supports governance features like circuit breaking and rate limiting.
- Isolation & fault tolerance: On the evaluation side (e.g., our KernelBench-based Eval Server), we use subprocess isolation, timeout/fault categorization, and resource constraints to keep environmental instability out of the training hot path.
- Observability & maintainability: Training / routing / evaluation each expose their own metrics and feed a unified dashboard, which helps with issue localization and reproducible regression.
Summary: Server-based means clear system boundaries connected by standardized interfaces, enabling horizontal scale-out (more services/devices) and vertical evolution (richer reward and evaluation pipelines).
2.3 Why Triton
Our focus on Triton kernel generation isn’t about excluding CUDA. We choose Triton as the present main arena based on these engineering considerations:
- LLM-friendly abstraction level: Triton is a higher-level GPU programming DSL — concise semantics and strong templating — well-suited to LLM code generation and iteration.
- Cross-vendor availability: Triton runs on NVIDIA / AMD, making it easier to reproduce experiments and run fair comparisons across ecosystems; we also keep a CUDA / Triton dual-backend evaluation path.
- Evaluation ecosystem alignment: Benchmarks like KernelBench balance correctness and performance, covering common PyTorch <-> custom-kernel scenarios — ideal for a solid train-evaluate closed loop.
- Long-term evolution: Using Triton as a baseline doesn’t block later expansion to other DSLs or domain-specific kernels; it actually helps compare costs/benefits across abstraction levels under a consistent evaluation protocol.
Summary: Choosing Triton is an engineering-first stabilization strategy — iterate the model on a portable, evaluable abstraction layer, while keeping CUDA and other backends available to ensure cross-stack alignment and verification.
3. Methodology
3.1 SFT Data Pipeline & Train
Goal: Use a small amount of SFT for a cold start so the model masters the KernelBench-style dialogue format (unified chat template). The main performance gains are then handed off to RL. SFT data pipeline repo: kernel_book.
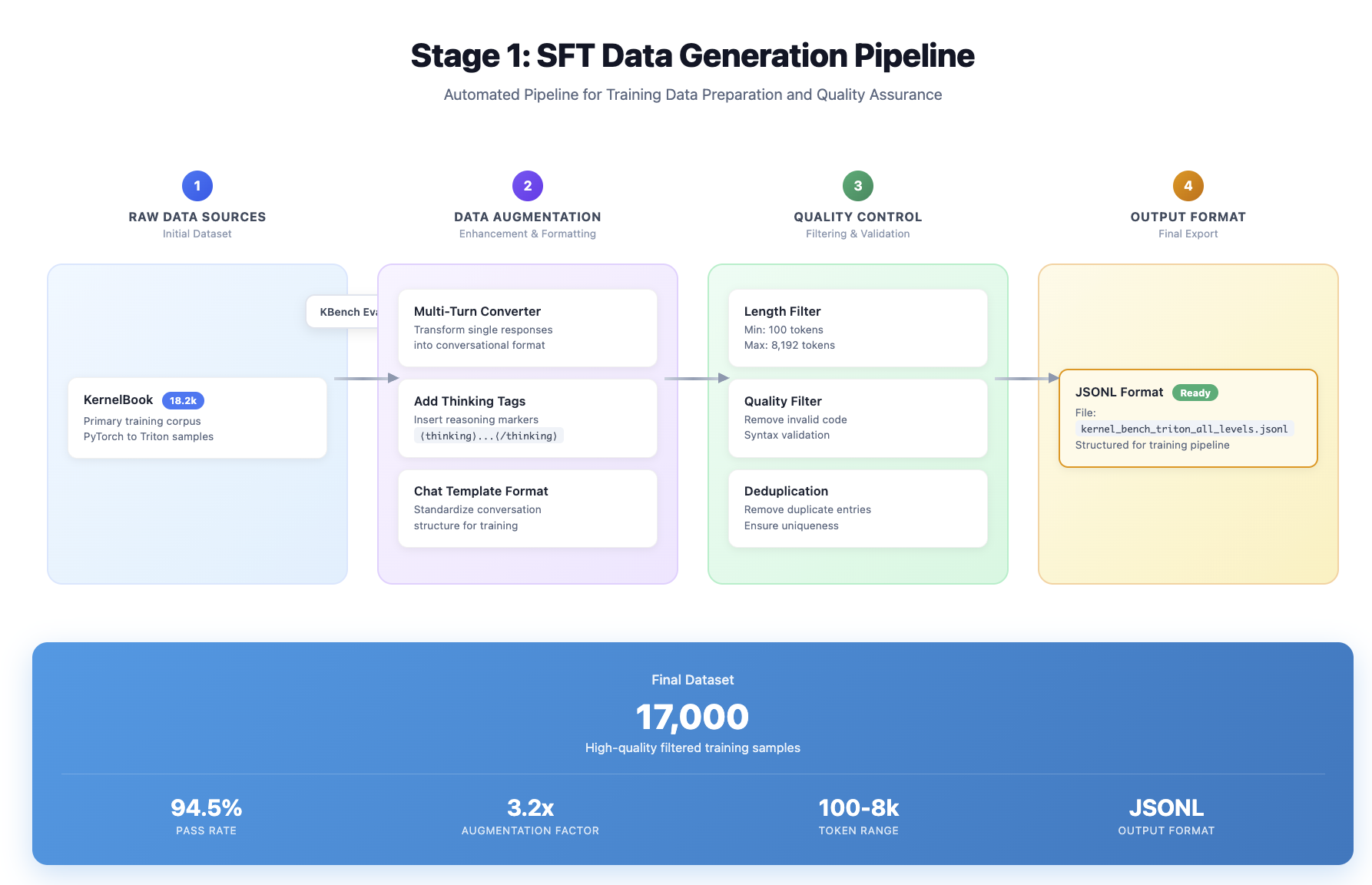
Data preprocessing
- Sources
- KernelBook: paired PyTorch <-> Triton samples with alignment for compilation and evaluation.
- Two additional 1k sets: multi-turn synthetic and thinking-tag (to strengthen reasoning structure on harder examples, generated by Claude-4.1-sonnet).
- Automatic pre-evaluation filters (run before importing for training)
- Compile check (ensure the Triton side compiles).
- Unit-test check (fixed random seeds, N-run consistency).
- Performance alignment (relative speed vs. the PyTorch baseline). These criteria mirror KernelBench’s evaluation philosophy, simplifying later unification with RL/Eval.
- Length & quality filtering: Aggressively remove extremely long samples (in practice, strong filtering for samples >8k/10k tokens) to avoid SFT-time OOM and the model learning degenerate “overlong output” behavior.
Training recipe (cold start)
- Base model: Qwen3-8B (a reasoning-oriented base that better supports multi-turn RL).
- Epochs: 1-2 (objective: learn templates & interfaces, not full convergence).
- Script: run-qwen3-8B-kernelbook-sft.sh
Monitoring & acceptance
- During training: loss, effective-token ratio, and max-sample truncation rate.
- Post-training quick regression: run compile / unit / perf on a fixed small set to ensure it “speaks the right thing.”
Reference thread: We extended KernelBench’s Eval backend to support multi-turn for PyTorch -> Triton tasks in KernelBook.
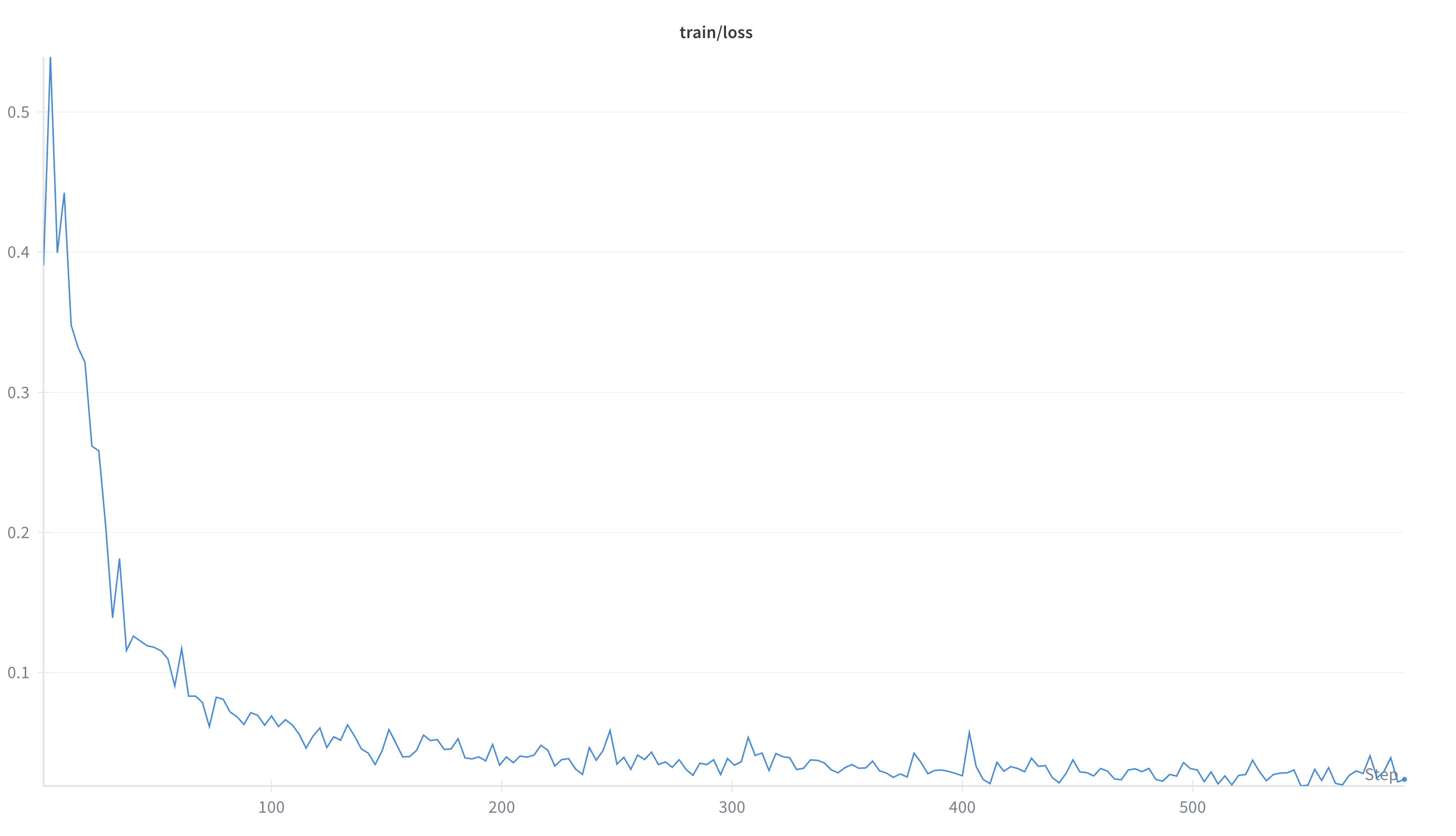
3.2 Server-based Rollout + Buffer + KBench Eval
Design objective: Completely decouple the environment (Agent / evaluation) from training / inference; natively support async concurrency, fault tolerance, and horizontal scaling; and feed back unified rewards to the trainer.
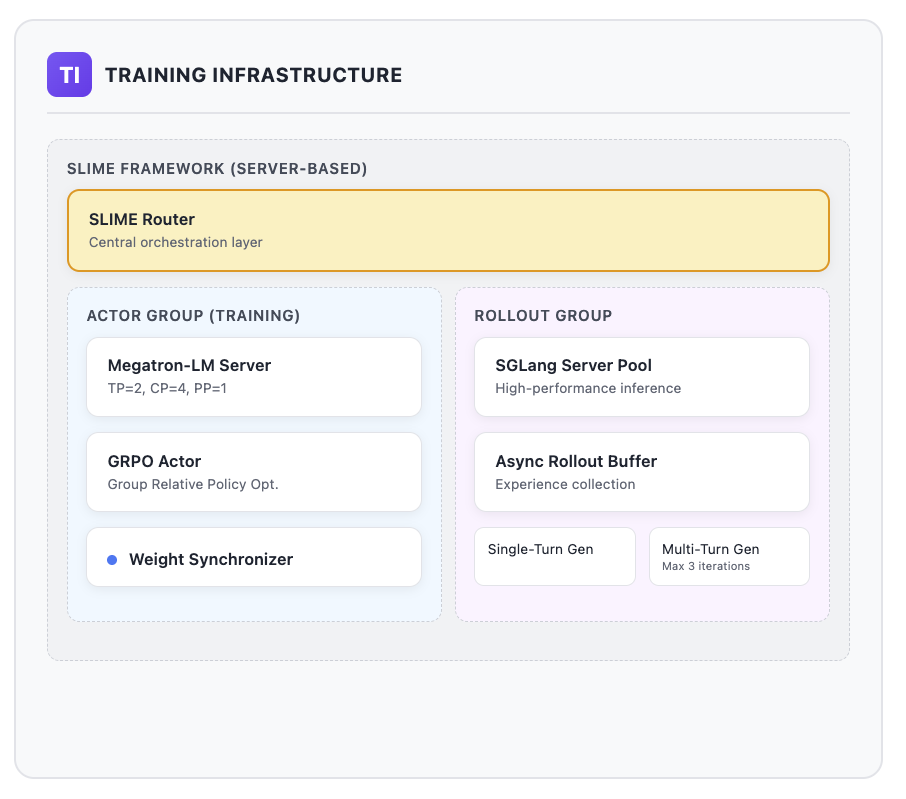
3.2.1 Components overview
- SGLang Router (Rust). Manages multiple inference instances (NV / AMD) and exposes OpenAI-style HTTP endpoints.
- Rollout Buffer (independent service). Aggregates per-group multi-sample rollouts (e.g., n=8), then runs statistics -> validity check -> per-item filtering -> reward normalization -> padding; emits stable, batched formats to the trainer.
- Generator (per task).
*_generator.py(one class for single-turn, one for multi-turn); drives environment interaction and assembles evaluation requests. - KBench Eval Server (robust). Subprocess isolation, 600s timeout, fault classification (
memory_fault/segfault/illegal_access/shared_mem_exceeded/timeout/syntax_error), supports CUDA / Triton dual backends; returns structured raw_reward and detailed rollout_log. - Trainer (GRPO, etc.). Consumes standard batches from the Buffer, computes advantages, and updates parameters.
3.2.2 Architecture Map
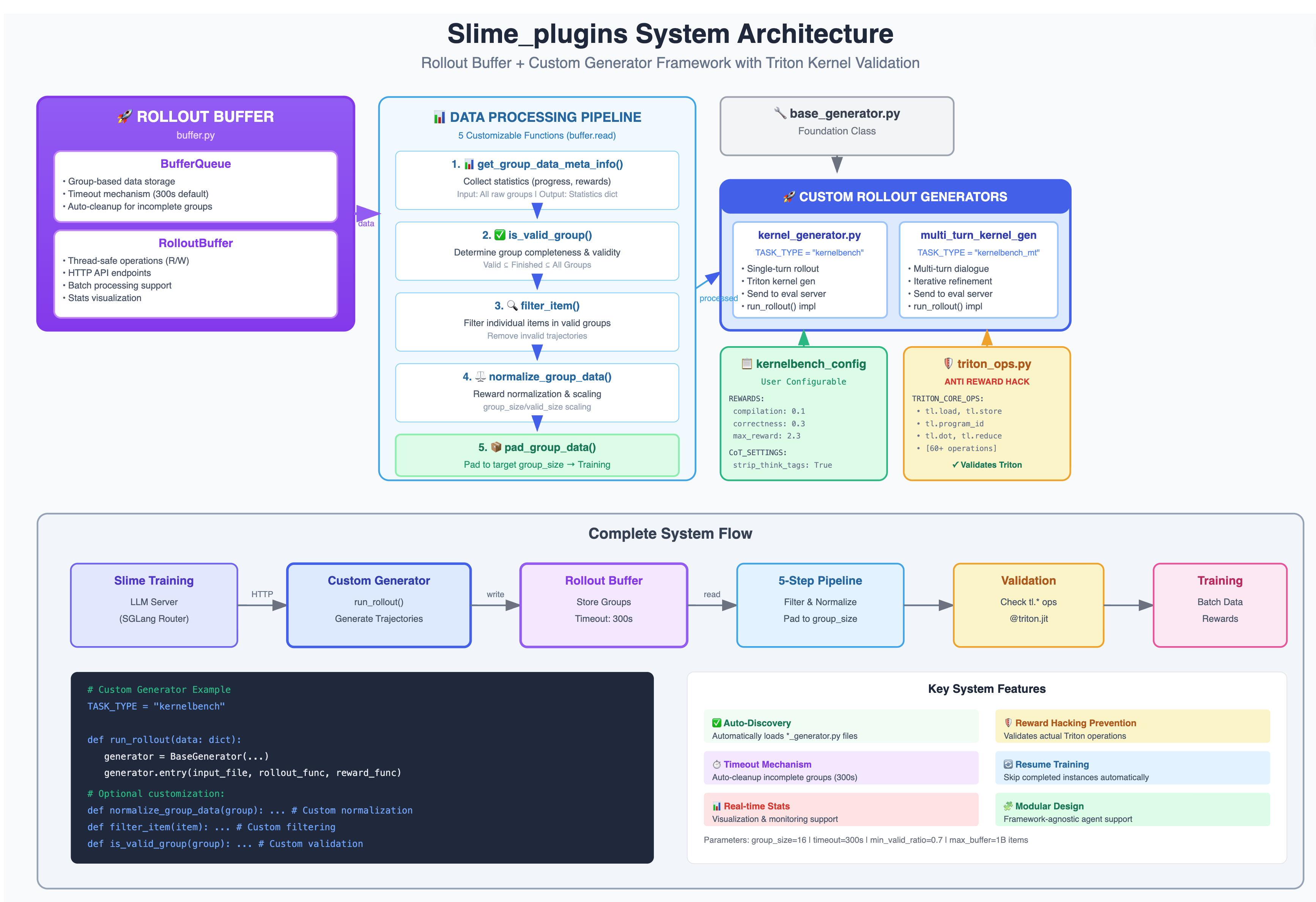
3.2.3 Buffer 5 hooks (Customizable)
get_group_data_meta_info()— progress stats and reward distribution.is_valid_group()— whether a group is “complete & valid.”filter_item()— per-item filtering (e.g., compile failure, format violation).normalize_group_data()— normalize/scale rewards only for valid items; keep original values in raw_reward.pad_group_data()— pad to a fixed group_size to keep batches well-shaped.
Recommended key settings
group_size=n_samples_per_prompt(commonly 8)min_valid_group_size_ratio= 1.0 (strict at group granularity)min_valid_item_size_ratio>= 0.7 (minimum valid ratio inside a group)- Timeouts:
group_timeout_seconds= 300,min_timeout_group_size_ratio= 0.7 - Capacity:
max_buffer_size= 1e9
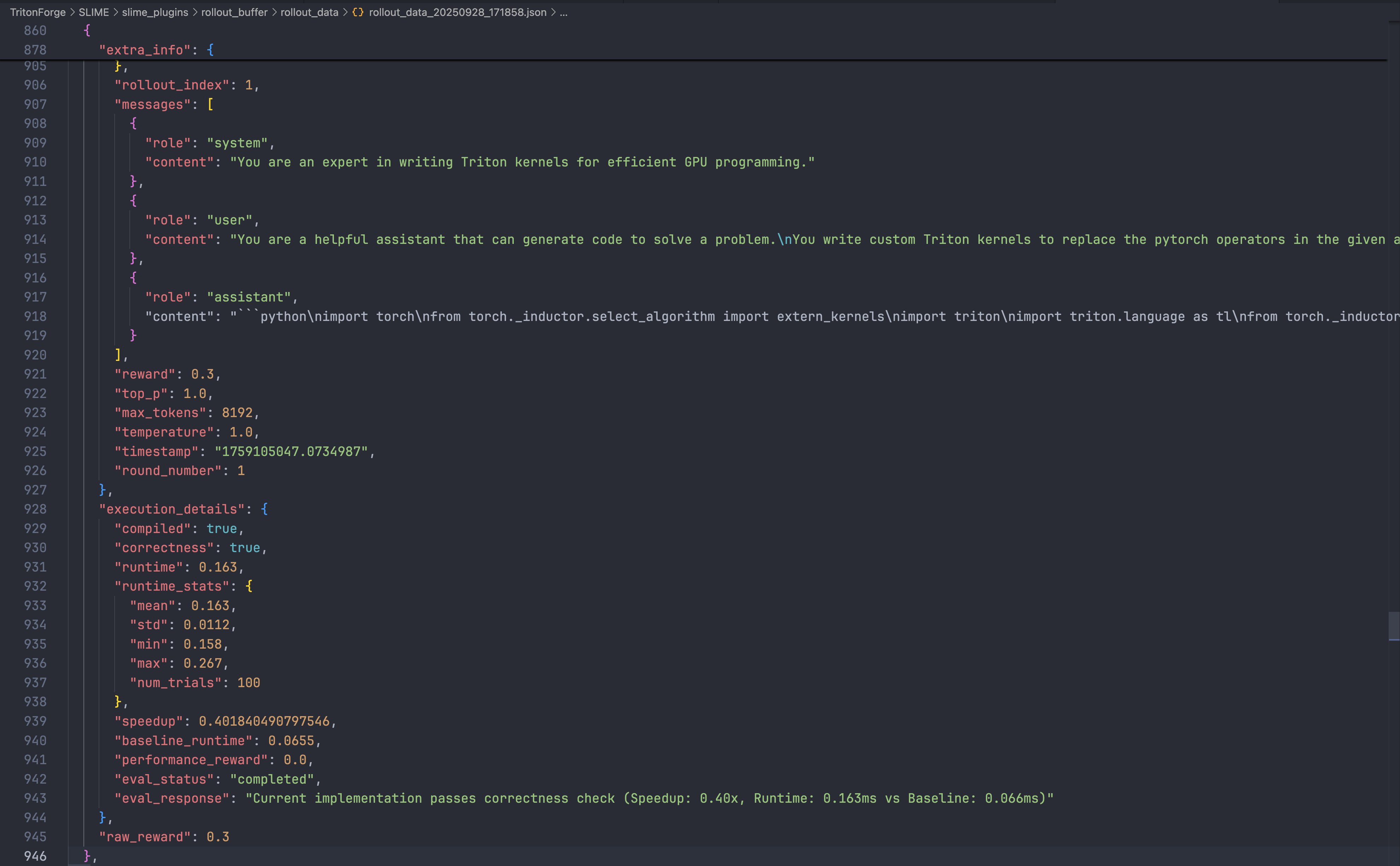
3.2.4 KBench Eval Server
- POST
/eval->KernelExecResult{ compile_ok, pass_rate, perf_stats, raw_reward, fault_type? }- Inputs:
original_model_src,custom_model_src,backend("cuda"/"triton"),seed_num,num_correct_trials,num_perf_trials,measure_performance,preferred_device - Mechanics: source via Base64, 600s timeout, subprocess isolation, signal capture (SIGSEGV / SIGABRT).
- Inputs:
- GET
/healthGET/gpu_status-> GPU availability & fault counters - POST
/reset_gpu/{id}POST/reset_devicesPOST/cleanup-> recovery & cleanup.
Evaluation criteria and sample sets track KernelBench to keep train-eval closure consistent and comparable.

3.3 RL Training (GRPO-first)
Strategy: First get GRPO fully working end-to-end with monitoring; GSPO / TIS interfaces are already wired for systematic A/B comparisons next.
Minimal training loop
- Data source: standardized batches from the Buffer (group-normalized/padded; raw_reward retained).
- Loss & constraints:
- Advantage estimation based on
raw_reward(closer to real task returns). - Standard KL regularization (target/penalty, either implementation).
- Gradient clipping & stabilizers (NaN guard, masking inactive items).
- Advantage estimation based on
- Scheduling: decoupled from the Router’s pool/routing; trainer simply pulls batches.
- Monitoring: raw_reward histogram, compile_pass@k, correctness_pass@k, distribution of log(speedup), KL / step size.
Single-turn vs. Multi-turn
- Single-turn: one generation + one evaluation; faster convergence, higher throughput.
- Multi-turn: self-correction / retries across turns, longer trajectories; reasoning bases are more stable; strictly cap lengths and cache intermediate states.
Hyperparameters (reference only)
- Sampling:
n_samples_per_prompt= 8,max_new_tokens= 8k (task-dependent) - Training:
global_batch_sizein {32, 64}, LR/weight decay follow standard schedules. - Scripts: run_agent_kbench_qwen3_8B_sft_amd_singleturn.sh
4. Results
Summary (reported as “percentage-point increase / relative gain %“)
| Setting | Metric (pre -> post) | Delta (pp) | Relative Gain |
|---|---|---|---|
| Single-turn @ AMD (Qwen3-8B-SFT) | 0.11563 -> 0.17500 | +5.94 pp | +51.3% |
| Multi-turn @ NV (Qwen3-8B-SFT) | 0.24 -> 0.36 | +12.00 pp | +50.0% |
| Single-turn @ NV (Qwen3-8B-SFT) | 0.102 -> 0.223 | +12.10 pp | +118.6% |
Calculation rules:
-
Percentage-point increase (pp) =
-
Relative gain =
-
Single-turn @ AMD: from 0.11563 to 0.175, +5.94 pp (around +51.3% relative gain)
- Multi-turn @ NV: from 0.24 to 0.36, +12.00 pp (around +50.0% relative gain)
- Single-turn @ NV: from 0.102 to 0.223, +12.10 pp (around +118.6% relative gain). GRPO still shows some stability issues; will compare with GSPO and DAPO soon.
- Multi-turn @ AMD: Bug under fix; results will be added using the same evaluation protocol. Track progress via issue #1.
5. Conclusion
- What we built. On slime (SGLang-native) + Megatron, we implemented a server-based closed loop for multi-turn RL — standardizing Rollout -> Buffer -> KernelBench Eval -> Train — and reproduced it across NVIDIA/AMD. For Triton kernel generation, both single-turn and multi-turn generators run end-to-end with unified logging for raw_reward / compile / pass / perf.
- Quantified gains:
- Single-turn @ AMD (Qwen3-8B-SFT):
raw_reward: 0.11563 -> 0.17500, +5.94pp (approx. +51.3%) - Multi-turn @ NV (Qwen3-8B-SFT):
raw_reward: 0.24 -> 0.36, +12.00pp (+50.0%) - Single-turn @ NV (Qwen3-8B-SFT):
raw_reward: 0.102 -> 0.223, +12.10 pp (approx. +118.6%)
- Single-turn @ AMD (Qwen3-8B-SFT):
- Key takeaways:
- Reasoning-oriented bases are more stable — multi-turn RL converges significantly better than with general instruction-tuned bases.
- Server-based decoupling meaningfully shields the training core from environment instability (async / rate limiting / circuit breaking live in the routing & eval planes).
- SFT only for cold-start; focus the lift on RL. Strong filtering of ultra-long / anomalous samples avoids SFT OOM and “bad-pattern” learning.
- Gaps & next steps. We’re standardizing results for Single-turn @ NV (Qwen3-8B-SFT) and Multi-turn @ AMD under the same protocol; on the eval side, we’ll harden a unified panel consolidating speed metrics (fast_p / speedup@p) with correctness/compile, to enable apples-to-apples comparisons.
6. Roadmap
Near term (engineering stabilization)
- Fix AMD multi-turn path: Focus on eval sandboxing and resource isolation; resolve MI300X multi-turn process/CPU anomalies; add Multi-turn @ AMD results under the same evaluation protocol.
- Unified evaluation panel: Cement the four core metrics raw_reward / compile_ok / pass@k / log(speedup) and their distributions.
- Reproducible scripts/config (done): Clean entry points and default parameter sets; add minimal single/multi-turn repro cases and regression suites.
Mid term (capability expansion)
- Algorithms: Systematic comparisons of GRPO / GSPO / TIS within the same loop; integrate reward decomposition and delayed-reward backprop.
- Models: Support MoE and larger parameter models (e.g., Qwen3-30B-A3B).
- Agentic Tool-Calling: Bring toolchain calls and environment state memory into a standard trajectory format.
- Scale-out: NV/AMD multi-node expansion.
Long term (evaluation & ecosystem)
- Evaluation bed upgrade: Stay aligned with KernelBench; expand operator sets; build a public leaderboard.
- slime sync: Track and sync with slime updates roughly monthly.
- Open-source collaboration: Further document slime’s plugin interfaces to lower task-migration costs.
7. Acknowledgements
- KernelBook / KernelLLM (GPUmode & Meta). Early experiments benefited greatly from KernelBook’s paired PyTorch <-> Triton samples; we also used KernelLLM (Llama-3.1-8B-Instruct) as a starting point. Together they inspired the “SFT cold-start -> RL” path.
- Kevin: Multi-Turn RL for Generating CUDA Kernels. Shaped our multi-turn generator and Buffer design with its training paradigm for long trajectories and reward attribution.
- KernelBench: Can LLMs Write Efficient GPU Kernels? Unified correctness + performance under one evaluation protocol and introduced fast_p, which guided our Eval Server and metrics panel design.
- SGLang / slime communities. Provided robust soil for server-based inference routing and RL frameworks.
- RLsys-Foundation / TritonForge partners & contributors. Offered a strong base and ongoing support for scripting and reproducibility across NV/AMD ecosystems.