Github 仓库(全开源)
GitHub: https://github.com/RLsys-Foundation/TritonForge
参与者
Jin Pan, Xiang Long, Chengxing Xie, Kexun Zhang, Haoran Wang, Junrong Lin, Yuzhen Zhou, Jiajun Li, Yang Wang, Xiaodong Yu, Gowtham Ramesh, Yusheng Su, Zicheng Liu, Emad Barsoum
1. TL;DR
TritonForge 是一个面向 多轮 Agent 任务 的 Server-based RL 训练与评测闭环, 以 slime(SGLang-native)+ Megatron 为底座, 聚焦 Triton 内核生成 在 NVIDIA 与 AMD 双生态的稳定、可扩展实践。 设计目标是把”多轮 RL 在真实环境中的不稳定性”变成可落地、可放大、可维护的系统能力。
在方法与任务设置上, 我们受到 Kevin(多轮 RL 生成 CUDA 内核) 与 KernelBench(内核正确性与性能评测基准) 的启发; 二者分别体现了多轮 RL 训练范式与工程化评测口径。
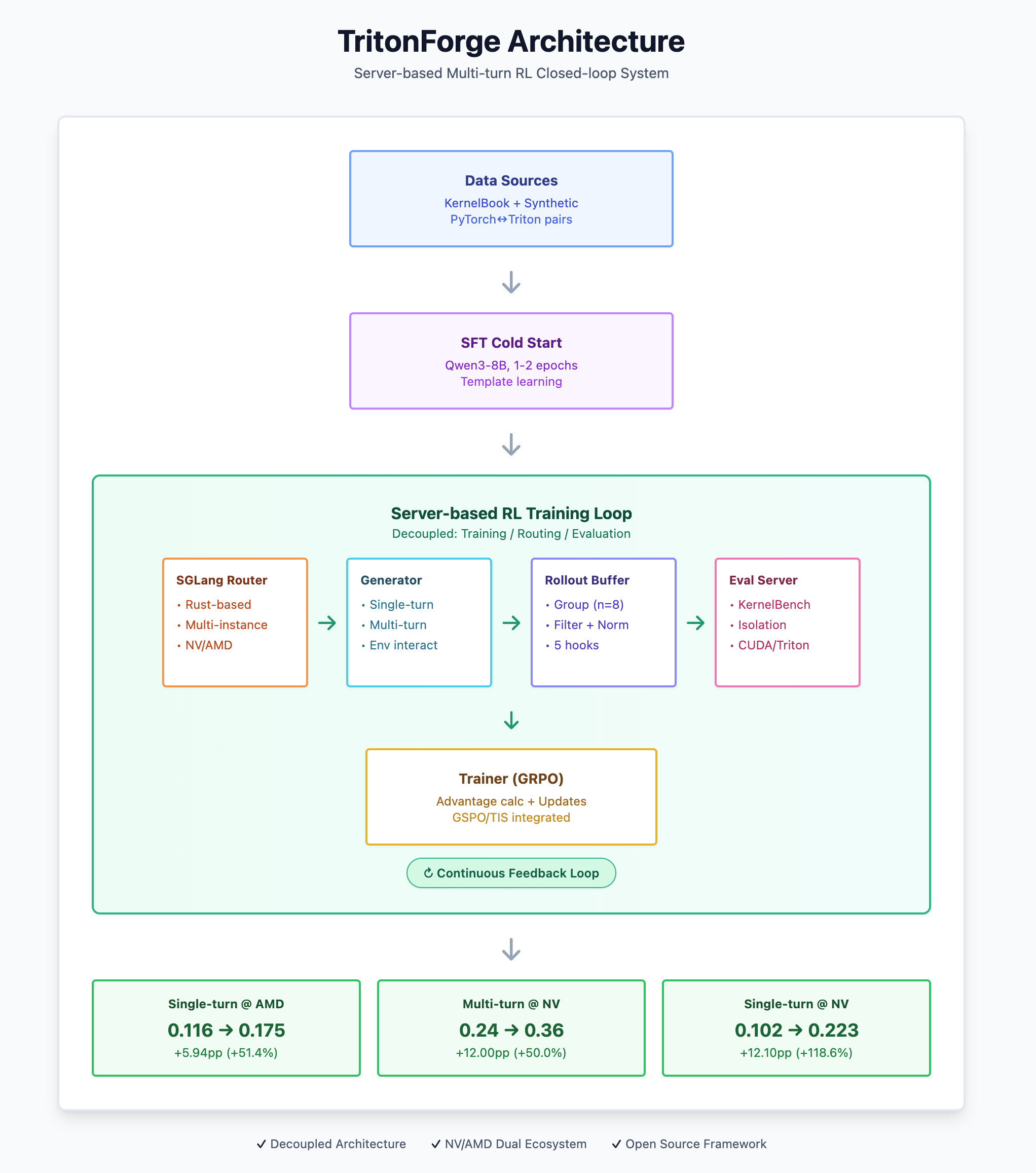
- 架构主张: Server-based 将 训练 / 路由 / 评测 解耦; SGLang Router 原生支持多推理服务与高并发; Buffer 以”组”为单位做 多样本采样(如 n=8)-> 过滤 -> 归一化 -> 填充, 统一 raw_reward 口径。
- 方法速览:
- SFT 冷启动(KernelBook 风格化数据; 极端长样本过滤避免 OOM);
- RL(GRPO 为主, GSPO / TIS 已打通, 便于后续横评);
- Eval Server 基于 KernelBench 后端做工程增强(子进程隔离、超时 / 故障分类、CUDA / Triton 双后端)。
- 早期结果(on Qwen3-8B-fine-tuned):
- Single-turn @ AMD: 0.116 -> 0.175, +5.94 个百分点(约+51.4%)
- Multi-turn @ NV: 0.24 -> 0.36, +12.00 个百分点(+50.0%)
- Single-turn @ NV: 0.102 -> 0.223, +12.10 个百分点(约+118.6%)
- Multi-turn @ AMD: 已定位到问题, 正在修复中
- 开源与可扩展性: 我们开源了端到端 Server-based 框架与 slime_plugins(单 / 多轮 kernel generator、Buffer 五件套钩子), 采用 slime + SGLang 的范式, 便于未来计划接入 更多算法(GRPO / GSPO / TIS / …)、MoE 模型, 以及完整的 Agentic tool-calling 工作流。
- 推荐阅读(灵感来源):
- Kevin: Multi-Turn RL for Generating CUDA Kernels(训练框架建立在未开源的 OpenRLHF + vLLM + DeepSpeed ZeRO-3 之上, 多轮 RL 适配真实环境与长轨迹)
- KernelBench: Can LLMs Write Efficient GPU Kernels?(250 个 PyTorch-CUDA 场景、兼顾正确性与性能的评测框架与指标设计)
- KernelBook / KernelLLM: PyTorch<->Triton 成对样本数据集; 配套 KernelLLM(Llama-3.1-8B-Instruct); 激发我们采用 SFT 冷启动 -> RL 的路线 — Dataset
2. 技术选型 / 追根溯源
2.1 Why Slime?(From verl -> slime)
最开始的起点
我们最初计划基于 veRL 完成整套多轮 RL 流水线:
- veRL 已经合入了 SGLang 异步多轮 rollout 支持(PR #1037), 与我们要做的多轮 Agent 训练方向高度一致。
- 同时我们提交了 SGLang PR(#4848), 探索在 veRL 中对 Server-based rollout 的原生支持。
- 早期设计文档也以 “完全 Server-based 的框架” 为蓝本(进程间通信、异步并行、与 Agent 环境解耦等)。 设计文档
- 与社区同伴也讨论过非常全面的 veRL x SGLang 的 Roadmap。 讨论
现实约束与工程取舍
- 今年五月, 社区里出现了基于 固定 veRL 版本 打包出的方案(例如 SkyRL), 这条路线在特定环境下跑通度很高, 但我们内部评估时还需要额外对接 AWS Cloud / OpenHands 等依赖, 整体上线门槛偏高, 短期不利于我们快速把 Server-based 多轮训练链路”全栈贯通”。 代码与说明: SkyRL
转向 Slime 的理由
- SGLang-native、Server-based 生而干净: Slime 把训练与推理-路由天然解耦, 接口轻量, 方便我们把 Rollout Buffer / Eval Server 作为独立服务拉起并编排。
- 落地效率: 在不牺牲可扩展性的前提下, Slime 让我们更快把 “多轮 Agent 真实环境—评测—训练” 闭环搭好, 并逐步开源化。
- 长期演进空间: Slime 的插件化设计(generator、buffer 五件套钩子)与 SGLang Router 的多后端路由很好契合我们后续要支持的 MoE、更多 RL 算法、Agentic tool-calling。
小结: 我们不是”由 A 转投 B”, 而是在 “快速跑通可维护的 Server-based 多轮 RL 闭环” 这一目标下, 选择了更贴合当下工程落地路径的 slime; 同时仍保持与 veRL 社区的良好接口与互通关注。
2.2 Why Server-based
核心诉求: 多轮 Agent 训练要同时面对”长轨迹、强工具依赖、真实环境不确定性”。 Server-based 架构把模型推理 / 训练控制与环境 / 评测彻底解耦, 是目前最能兼顾稳定性与可扩展性的形态。
- 解耦与可移植: Agent 环境可以在另一台机器 / 另一种语言运行; 模型侧可自由升级(不同框架、不同显卡、不同并行策略)而不影响环境逻辑。
- 天然异步与弹性: 请求-响应通过网络协议管理, 易于并发扩缩与弹性调度, 训练端减少”气泡”, 提高 GPU 利用率。
- 路由与治理: 依托 SGLang Router(Rust 实现) 管理高并发多推理服务, 支持熔断与限流等治理手段。
- 隔离与容错: 评测端(如我们的 KernelBench-based Eval Server)可子进程隔离、超时 / 故障分类、资源约束, 把环境不稳定性挡在训练主流程之外。
- 可观测与可维护: 训练 / 路由 / 评测三平面各自暴露指标, 统一回流仪表盘, 问题定位与回归复现实用。
小结: Server-based 让我们把”系统边界划清楚, 用标准化接口连接, 既方便横向扩展(更多服务 / 更多设备), 也方便纵向演进(更复杂的奖励与评测管线)。
2.3 Why Triton
我们专注 Triton 内核生成, 并不是排他性地替代 CUDA, 而是基于以下工程考量把 Triton 作为当前阶段的主战场:
- 对 LLM 友好的抽象层级: Triton 属于更高层的 GPU 编程 DSL, 语义紧凑、模板性强, 更贴合 LLM 的代码生成与修改循环。
- 跨厂可用: Triton 在 NVIDIA / AMD 上均可用, 便于我们在双生态上复现实验与做公平评测; 同时我们也保留 CUDA / Triton 双后端 的评测通道。
- 评测生态协同: 像 KernelBench 这类基准兼顾正确性与性能, 覆盖 PyTorch <-> 自定义内核 的常见场景, 有利于把”训练-评测”闭环做扎实。
- 长线演进: 以 Triton 为基线并不妨碍后续扩展到其他 DSL 或专业领域内核; 反而能帮助我们在相同评测口径下对比不同抽象层的收益与成本。
小结: 选择 Triton 是先把工程面打稳的策略—让模型在可移植、可评测的抽象层上持续迭代; 同时保留 CUDA 等后端通路, 保证结果在不同栈上的可对齐与可验证。
3. Methodology
3.1 SFT Data Pipeline & Train
目标: 用少量 SFT 做”冷启动”, 让模型学会 KernelBench 风格的对话范式与格式(Chat Template 统一), 然后把主要增益交给 RL。 SFT Data Pipeline Repo: kernel_book。
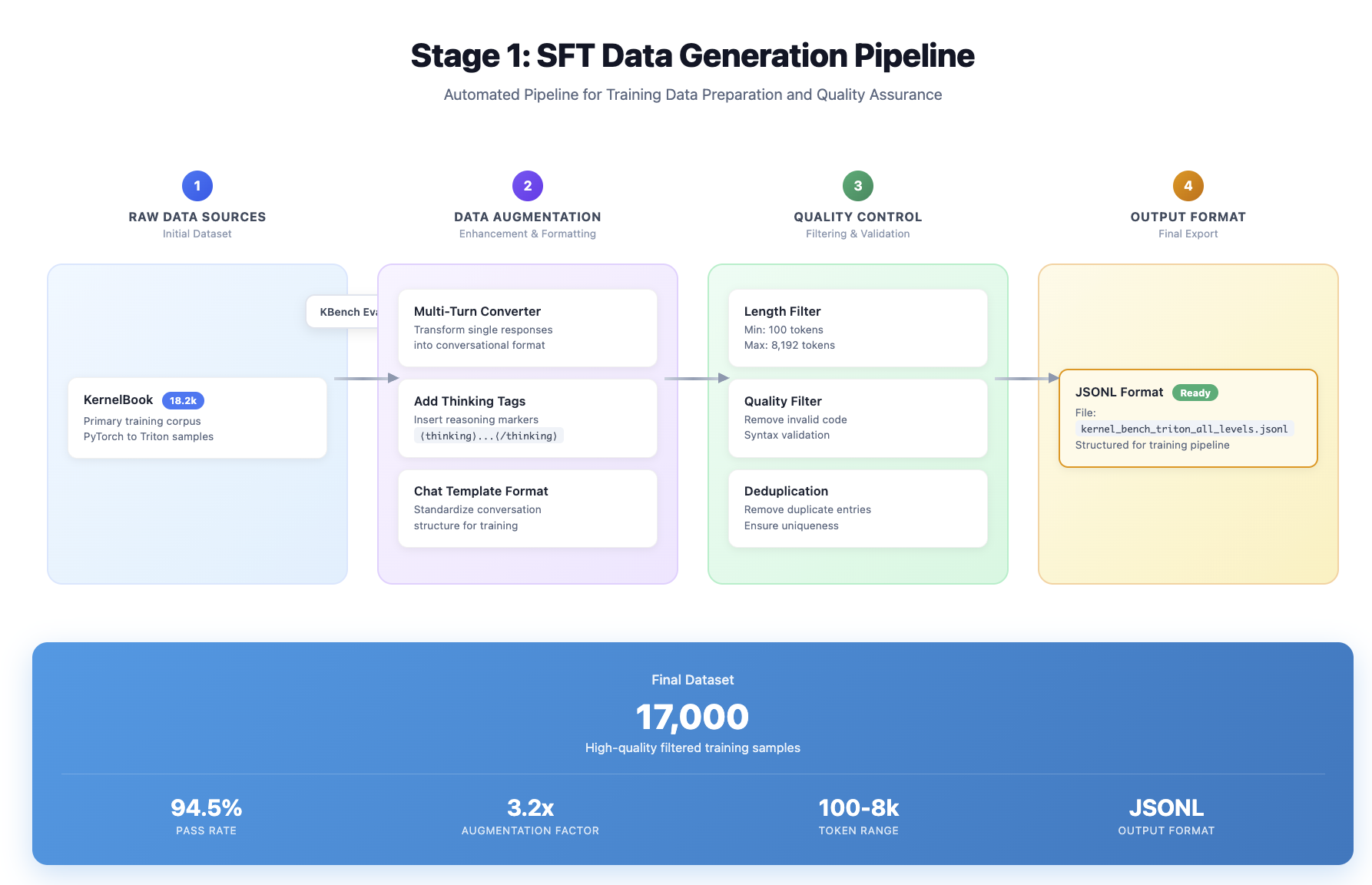
数据与预处理
- 语料来源:
- KernelBook(PyTorch<->Triton 成对样本, 含可编译与可测评的对齐数据)
- 分别 1k 的 multi-turn 合成与 thinking-tag(用于强化复杂样例的推理结构, 由 Claude-4.1-sonnet 生成)
- 自动评测过滤(在导入训练前执行):
- 编译检查(确保 Triton 侧可编译)
- 单测检查(随机种子、N 次一致性)
- 性能对齐(与 PyTorch baseline 的相对速度)。 上述口径与 KernelBench 的评测思想一致, 便于后续和 RL / Eval 统一
- 长度与质量过滤: 清理极端长样本(实践中对 >8k/10k token 的样本做强过滤), 避免训练期 OOM 与无效长输出模式学习。 因为我们也发现如果有这种超长 case 不仅质量比较低, 还会影响 SFT 的训练稳定性。
训练配方(cold start)
- 基座: Qwen3-8B(reasoning 基座更稳妥承接多轮 RL)
- 轮次: 1—2 epoch(目的: 学模板与接口, 不追求收敛)
- 脚本位置: run-qwen3-8B-kernelbook-sft.sh
监控与验收
- 训练期监控: loss、有效 token 比例、最长样本截断率。
- 训练后快速回归: 对固定小集合跑 compile / unit / perf 三项自测, 确保”会说正确话”。
参考脉络: 我们通过修改 KernelBench 的 Eval Backend 来对 KernelBook 里面的 PyTorch2Triton 进行了 multi-turn 的扩展
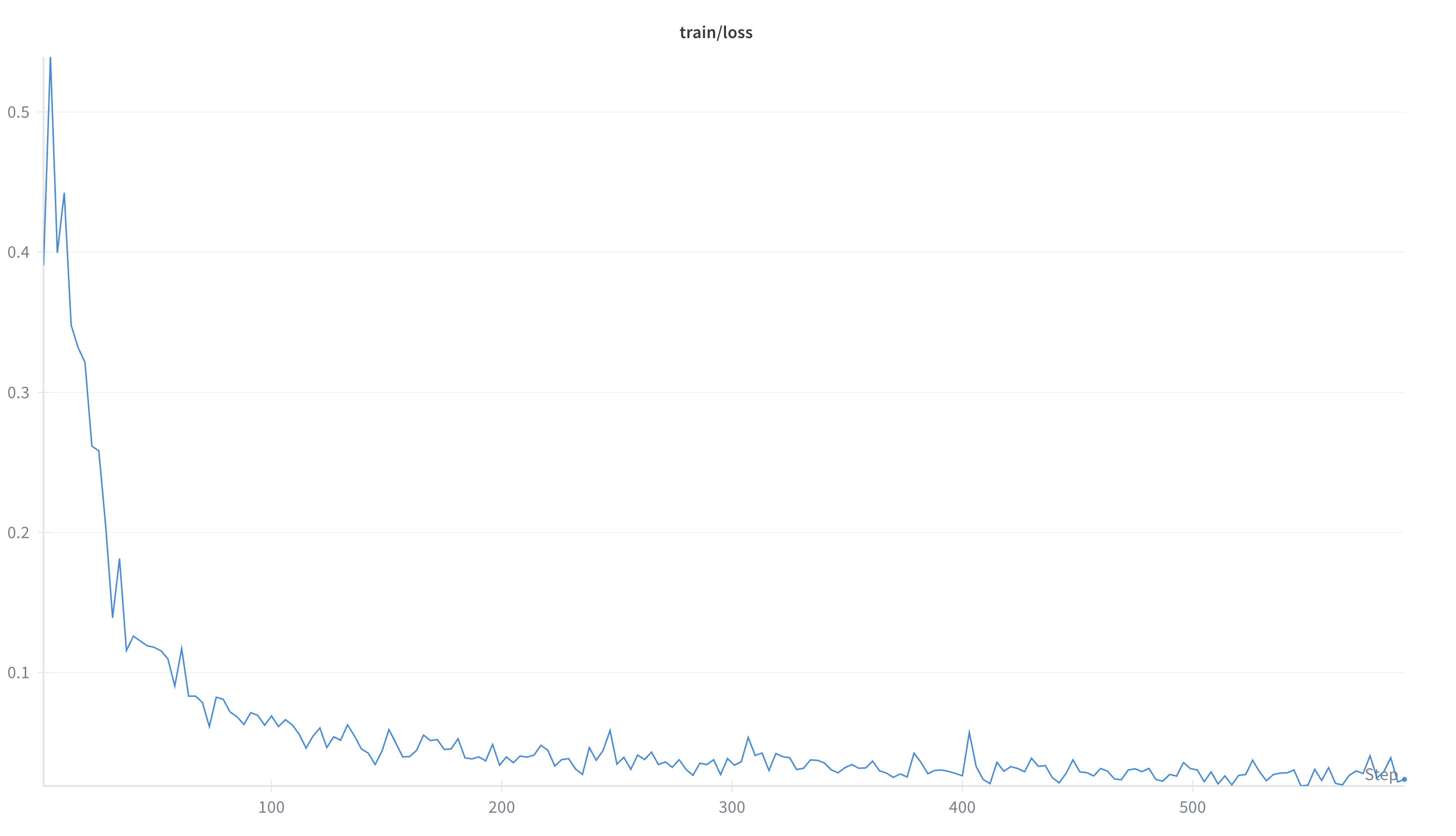
3.2 Server-based Rollout + Buffer + KBench Eval
设计目标: 把”环境(Agent / 评测)“与”训练 / 推理”彻底解耦; 天然支持异步并发、容错与横向扩缩; 统一奖励口径回流训练侧。
3.2.1 Components overview
- SGLang Router(Rust): 统一管理多推理实例(NV / AMD); 暴露 OpenAI-style / HTTP 接口。
- Rollout Buffer(独立服务): 按 group 聚合多样本采样(如 n=8), 执行统计 -> 有效性判定 -> 单项过滤 -> 奖励归一化 -> 填充五步, 并向训练侧按批吐出稳定格式。
- Generator(per task):
*_generator.py(单轮、多轮各一类), 负责驱动环境交互与组装评测请求。 - KBench Eval Server(Robust version): 子进程隔离、600s 超时、错误分类(
memory_fault/segfault/illegal_access/shared_mem_exceeded/timeout/syntax_error), 支持 CUDA / Triton 双后端, 返回结构化 raw_reward 与 rollout_log。 - Trainer(GRPO, etc): 消费 Buffer 的标准批次, 计算优势与更新。
3.2.2 Architecture Map
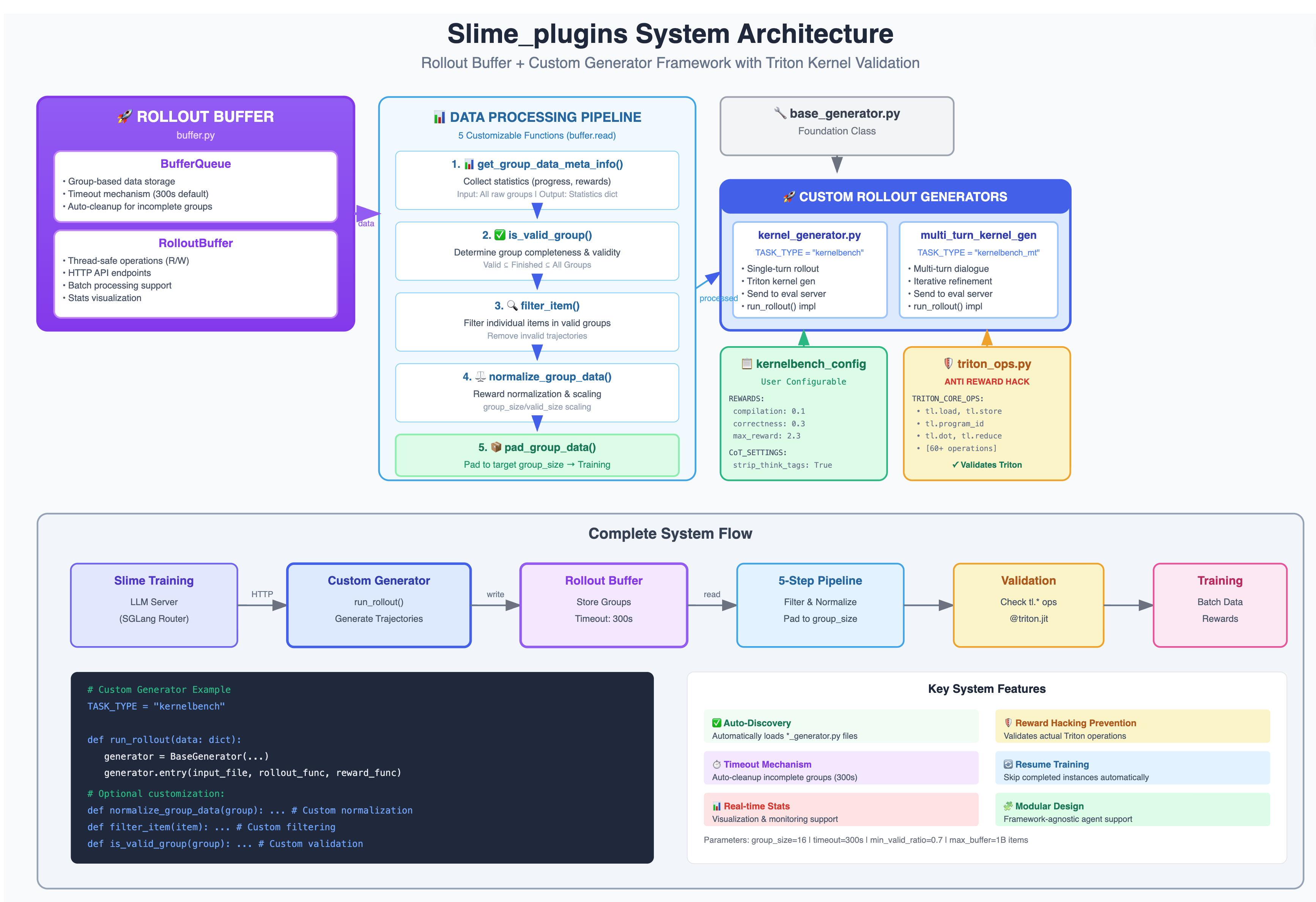
3.2.3 Buffer 五件套钩子(可选重写)
get_group_data_meta_info(): 统计进度与奖励分布is_valid_group(): 判定”完成且有效”的组filter_item(): 逐项过滤(如编译失败、格式不合规)normalize_group_data(): 只对有效项做奖励归一化 / 缩放, 原值保留到 raw_rewardpad_group_data(): 填充到固定 group_size(保证 batch 规整)
关键参数建议
group_size=n_samples_per_prompt(常用 8)min_valid_group_size_ratio= 1.0(组粒度把关, 失败样本依然入库, 但会在后续过滤 / 惩罚)min_valid_item_size_ratio>= 0.7(组内最小有效比例)- 超时:
group_timeout_seconds= 300,min_timeout_group_size_ratio= 0.7 - 容量:
max_buffer_size= 1e9
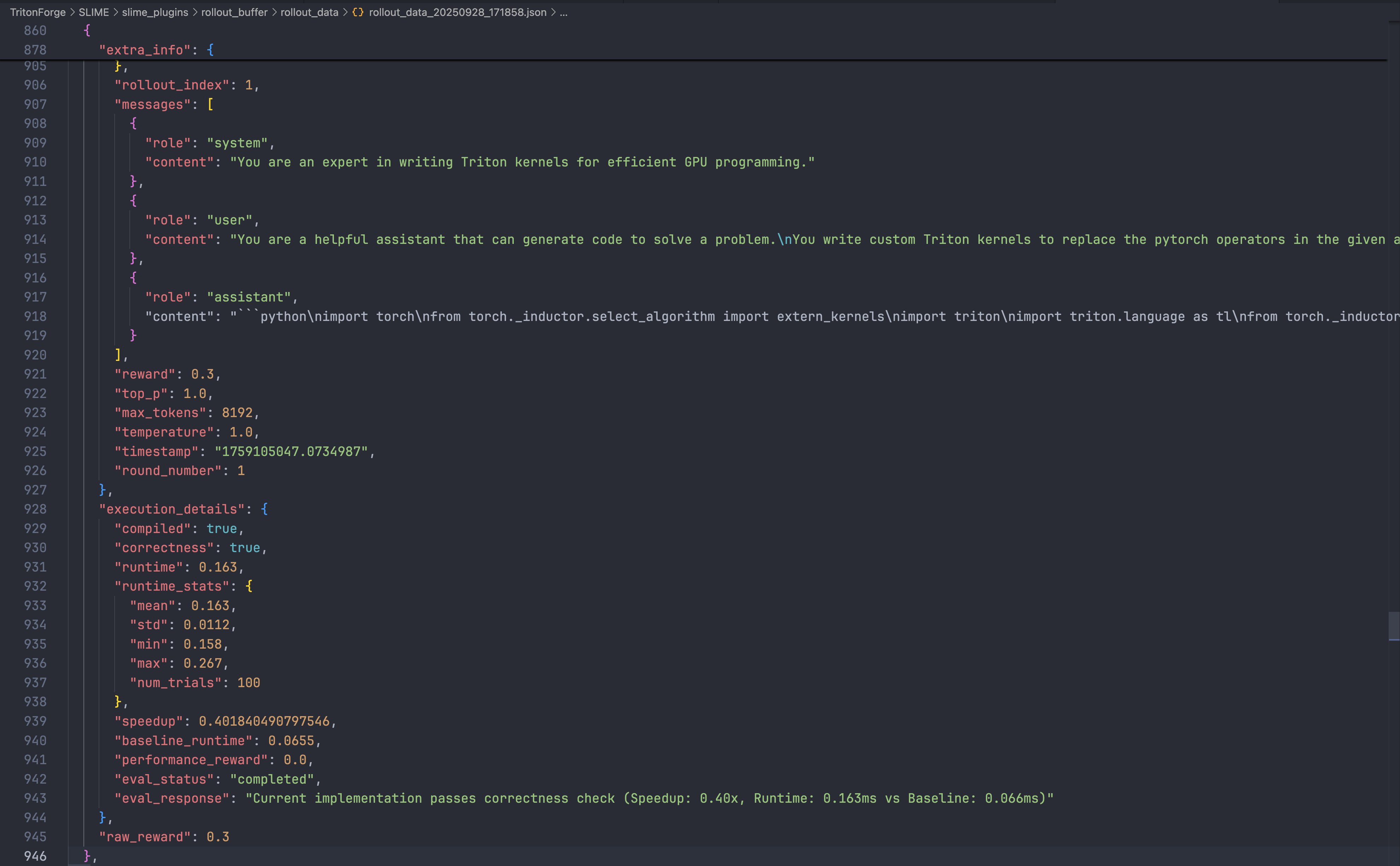
3.2.4 KBench Eval Server
- POST
/eval->KernelExecResult{ compile_ok, pass_rate, perf_stats, raw_reward, fault_type? }- 入口参数:
original_model_src、custom_model_src、backend("cuda"/"triton")、seed_num、num_correct_trials、num_perf_trials、measure_performance、preferred_device - 机制: Base64 传输源码、600s 超时、子进程隔离、信号捕获(SIGSEGV / SIGABRT)
- 入口参数:
- GET
/healthGET/gpu_status-> 统计 GPU 可用性与故障计数 - POST
/reset_gpu/{id}POST/reset_devicesPOST/cleanup-> 恢复与清理
评测口径与样例集合追踪 KernelBench, 以保证”训练-评测”闭环的一致性与可比性。

3.3 RL Training(GRPO-first)
策略: 先用 GRPO 跑通端到端与监控闭环; GSPO / TIS 已贯通接口, 后续做系统化横评。
训练最小闭环
- 数据来源: Buffer 标准批(组内已归一化 / 填充, 保留
raw_reward) - 损失与约束:
- 优势估计基于
raw_reward(更贴近真实任务收益) - 典型 KL 约束(target / penalty, 两种实现皆可)
- 梯度裁剪与稳定器(NaN guard、失活样本屏蔽)
- 优势估计基于
- 调度: 与 Router 的池 / 路由策略解耦(训练只”拉批”)
- 监控: raw_reward 直方图、compile_pass@k 比例、correctness_pass@k、log(speedup) 分布、KL / 步长
单 / 多轮差异
- Single-turn: generator 只做一次生成与评测, 收敛快、吞吐高。
- Multi-turn: 多轮自我修正 / 重试, 轨迹变长; reasoning 型基座更稳, 需严格限长与缓存中间状态。
典型超参(参考位点)
- 采样:
n_samples_per_prompt= 8、max_new_tokens= 8k(按任务调优) - 训练:
global_batch_size属于 {32, 64}、学习率 / 权重衰减按经验曲线 - 脚本位点: run_agent_kbench_qwen3_8B_sft_amd_singleturn.sh
4. 结果
Summary(按”百分点 / 相对提升%“汇总)
| Setting | Metric (pre -> post) | Delta(百分点, pp) | 相对提升 |
|---|---|---|---|
| Single-turn @ AMD(Qwen3-8B-SFT) | 0.11563 -> 0.17500 | +5.94 pp | +51.3% |
| Multi-turn @ NV(Qwen3-8B-SFT) | 0.24 -> 0.36 | +12.00 pp | +50.0% |
| Single-turn @ NV(Qwen3-8B-SFT) | 0.102 -> 0.223 | +12.10 pp | +118.6% |
计算方式:
-
百分点增幅(pp)=
-
相对提升 =
-
Single-turn @ AMD: 从 0.11563 提升到 0.175, +5.94 个百分点(约 +51.3% 相对提升)。
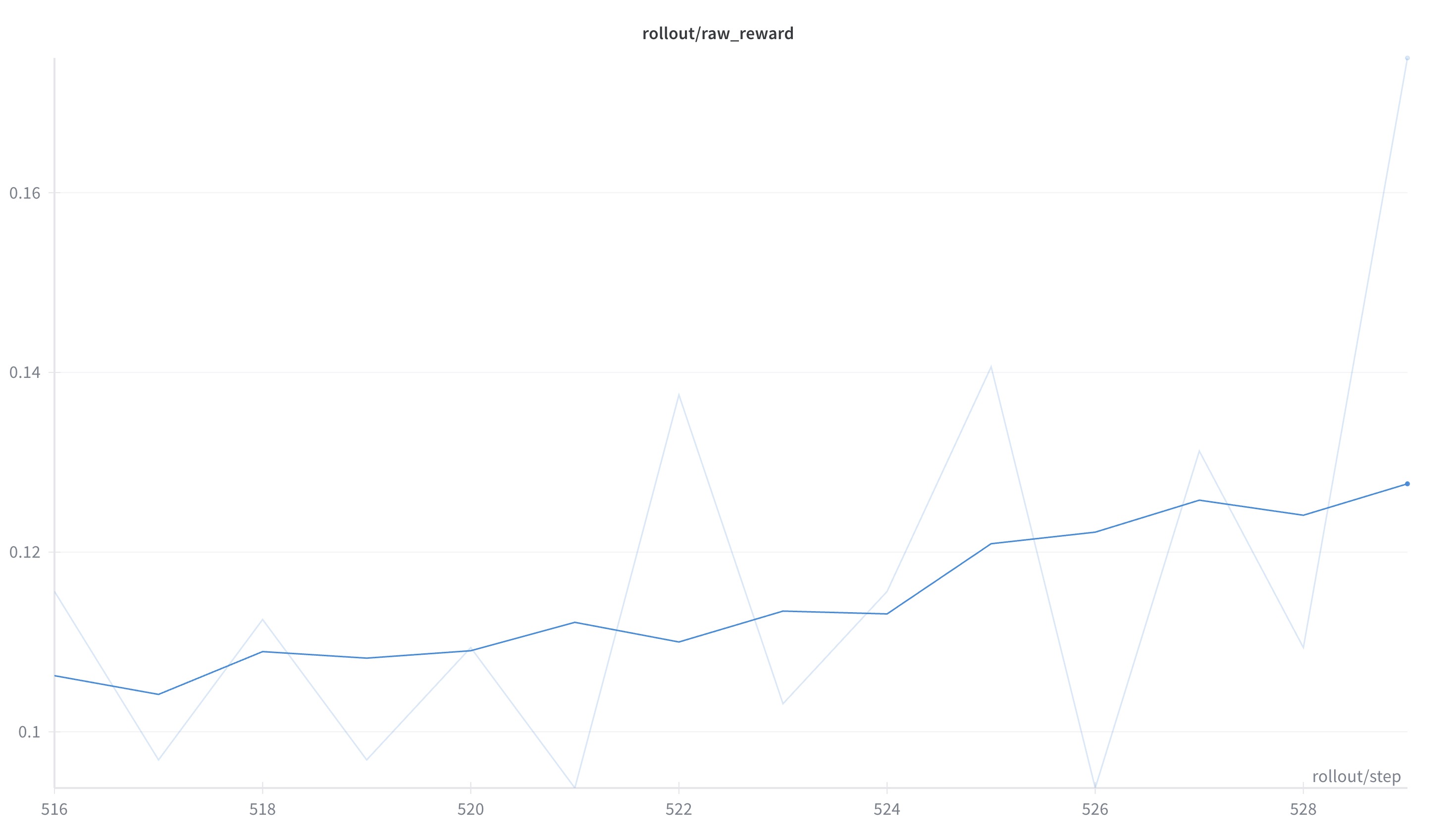
- Multi-turn @ NV: 从 0.24 提升到 0.36, +12.00 个百分点(+50.0% 相对提升)。
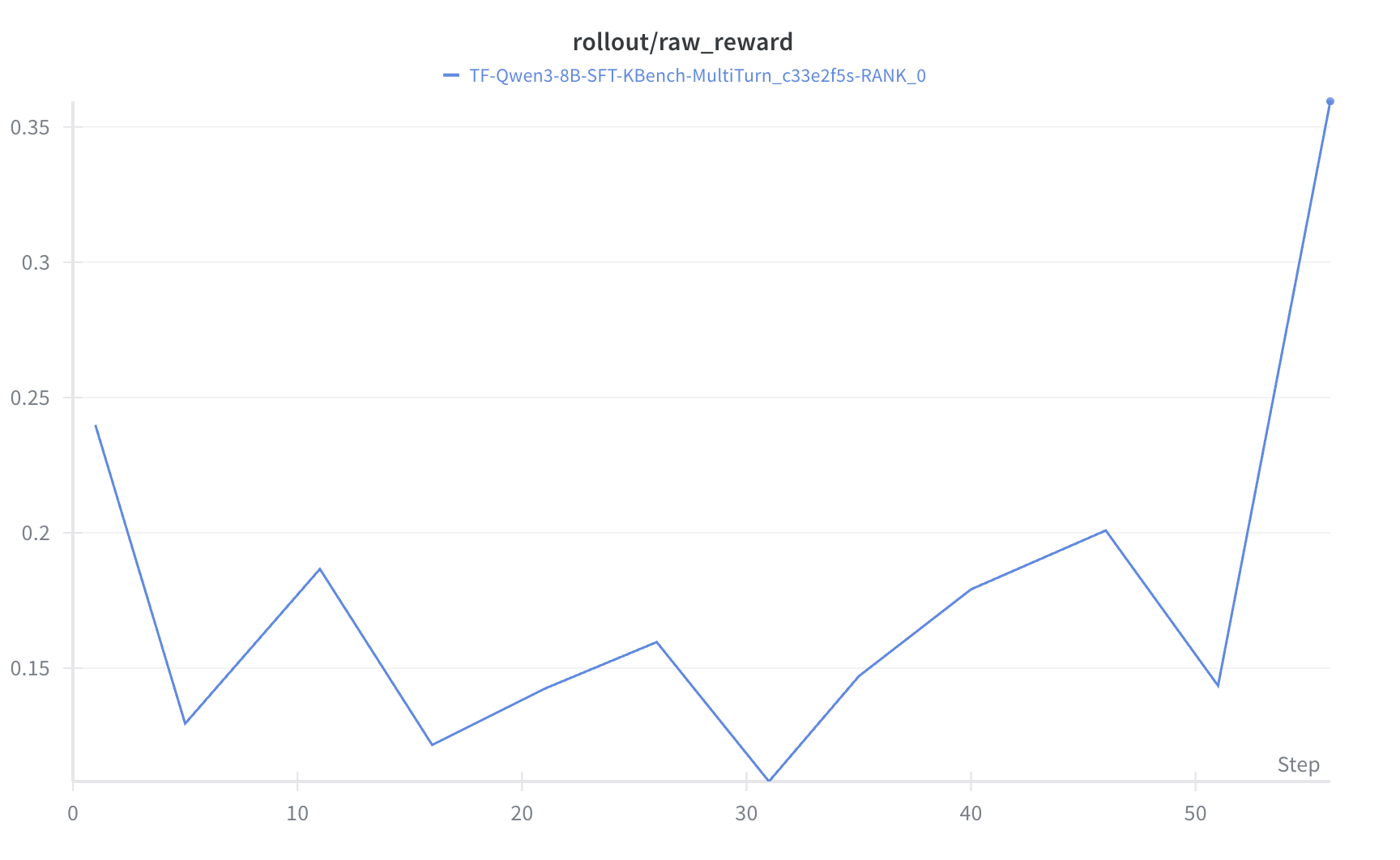
- Single-turn @ NV: 从 0.102 提升到 0.223, +12.10 个百分点(+118.6% 相对提升)。 目前的 GRPO 还是会有很多震荡, 考虑下一步用 GSPO 或者 DAPO 去做一轮对比实验。
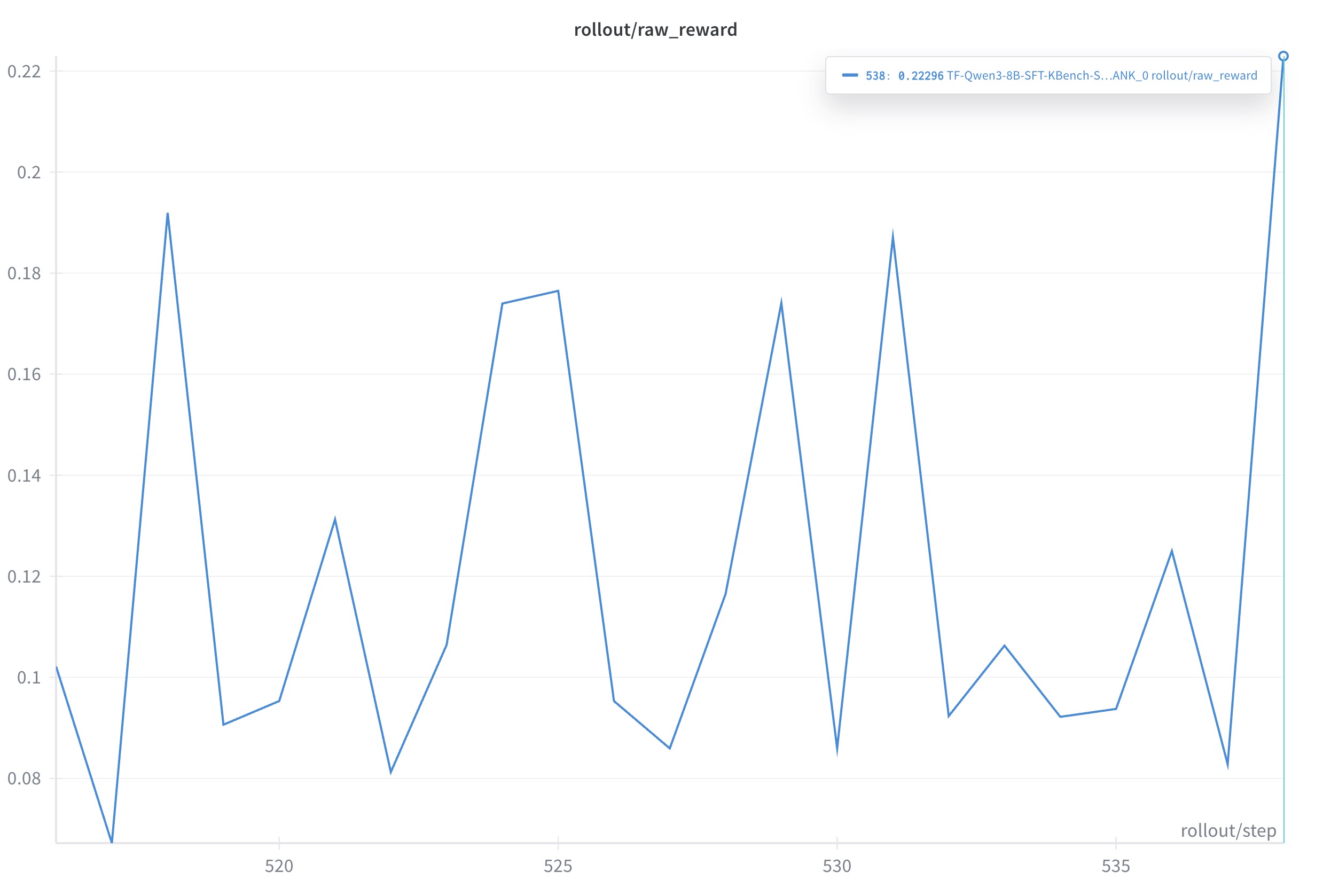
- Multi-turn @ AMD: 当前仍在修复 bug, 修复后按同一评测口径补充结果。 最新近况可以 track 这个 issue page: #1
5. 结论
- 我们做成的: 基于 slime(SGLang-native)+ Megatron 打造了一套 Server-based 的多轮 RL 训练-评测闭环, 把 Rollout -> Buffer -> KernelBench Eval -> Train 串成标准化流水线, 且 NV / AMD 双生态可复现。 框架已在 Triton 内核生成 任务上跑通单 / 多轮两类生成器、统一了 raw_reward / compile / pass / perf 的记录与回流口径。
- 可量化增益:
- Single-turn @ AMD(Qwen3-8B-SFT):
raw_reward: 0.11563 -> 0.17500, +5.94pp(约+51.3%) - Multi-turn @ NV(Qwen3-8B-SFT):
raw_reward: 0.24 -> 0.36, +12.00pp(+50.0%) - Single-turn @ NV(Qwen3-8B-SFT):
raw_reward: 0.102 -> 0.223, +12.10 pp(约+118.6%)
- Single-turn @ AMD(Qwen3-8B-SFT):
- 关键经验:
- Reasoning 基座更稳(多轮 RL 收敛显著好于通用指令基座)
- Server-based 解耦 能显著降低环境不稳定对训练主干的影响(异步 / 限流 / 熔断都能落地在路由与评测面)
- SFT 只做冷启动, 重心放在 RL; 同时对 超长 / 异常样本 做强过滤可避免 SFT / OOM 与”学习坏模式”
- 边界与待补: Single-turn @ NV(Qwen3-8B-SFT)与 Multi-turn @ AMD 正在按同一口径补全; 评测侧还需把 速度口径(fast_p / speedup@p) 与 正确性 / 编译 固化为统一面板, 便于横向对比。
6. Roadmap
近期(工程稳定化)
- AMD 多轮链路修复: 聚焦评测沙箱与资源隔离, 修复 MI300X 多轮训练时的进程与 CPU 异常; 补齐 Multi-turn @ AMD 的同口径结果。
- 统一评测面板: 固化四大核心指标 raw_reward / compile_ok / pass@k / log(speedup) 的统计与分布。
- 可复现脚本 / 配置(已完成): 清理脚本入口与默认参数集, 添加单 / 多轮最小复现用例与回归集。
中期(能力扩展)
- 算法扩展: 在同一闭环下系统化对比 GRPO / GSPO / TIS, 加入奖励分解与延迟奖励回溯策略。
- 模型扩展: 支持 MoE 与更大参数量 的推理池与训练配方(如 Qwen3-30B-A3B)。
- Agentic Tool-Calling: 把工具链调用与环境状态记忆纳入标准轨迹格式。
- Scale Out: NV / AMD 多节点 扩展, 评估吞吐 / 成本 / 稳定性曲线。
长期(评测与生态)
- 评测基座升级: 与 KernelBench 社区保持口径对齐, 增补更贴近生产场景的算子集与真实数据分布; 形成公开 leaderboard 与标准化报告模板。
- slime 更新: 与 slime 最新 update 尽量在一个月 sync up 一次。
- 开源协作: 把 slime 插件化接口(generator / buffer 钩子 / Eval API)进一步文档化, 降低任务迁移成本。
7. 致谢
- KernelBook / KernelLLM(GPUmode & Meta): 早期实验大量受益于 KernelBook 的 PyTorch<->Triton 成对样本, 也直接使用了 KernelLLM(Llama-3.1-8B-Instruct 基座) 作为起点, 这两者共同激发了我们采用 “SFT 冷启动 -> RL 后训练” 的路线。
- Kevin:Multi-Turn RL for Generating CUDA Kernels: 多轮 RL 在长轨迹上的训练范式与奖励归因给了我们多轮生成器与 Buffer 设计的重要启发。
- KernelBench:Can LLMs Write Efficient GPU Kernels?: 将正确性 + 性能纳入统一评测口径, 并提出 fast_p 指标, 为我们构建 Eval Server 与统一指标面板提供了清晰参照。
- SGLang / slime 社区: 提供了高质量的 Server-based 推理路由与 RL 框架土壤。
- RLsys-Foundation / TritonForge 合作伙伴与贡献者: 在 NV / AMD 双生态的脚本与复现实操上提供了坚实基座与持续支持。